[ad_1]
Je stuurt op rankings, organisch verkeer en omzet. Maar weet je ook wat Googlebot én crawlres van LLM’s zoals die van ChatGPT daadwerkelijk op je site aan het doen is?
Logfiles geven je daar inzicht in. Geen aannames, geen ‘ik denk dat Google dit ziet’ maar rauwe serverdata. Tijdens ISS Barcelona liet Julien Deneuville stap voor stap zien hoe je met logfiles slimmer en gerichter aan SEO kunt werken.
In deze blog neem ik je mee:
-
- Waarom ze krachtig zijn voor SEO
-
- Hoe je ze verzamelt en uitleest
-
- Welke concrete analyses je kunt doen
-
- En welke praktische learnings je eruit haalt.
Wat zijn logfiles eigenlijk?
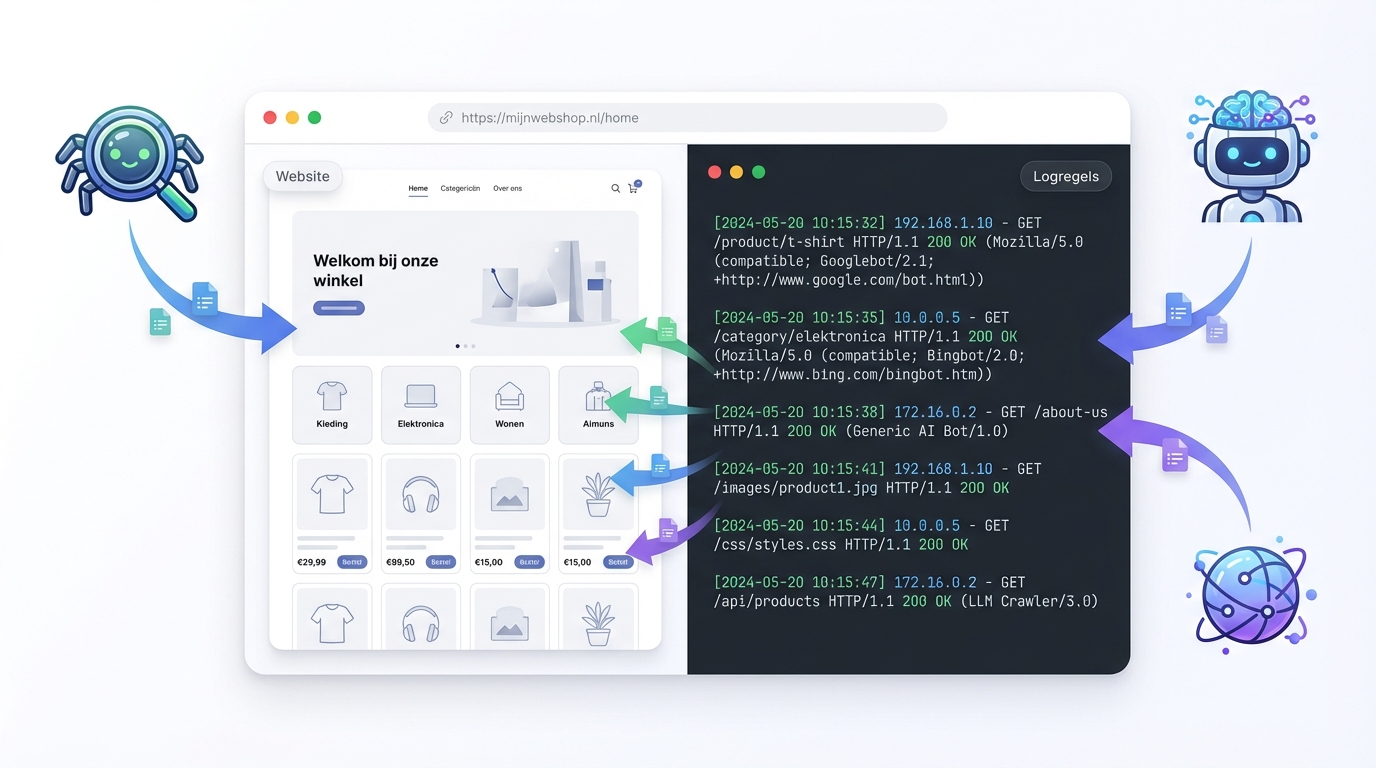
Elke keer dat een gebruiker of bot een pagina op je site bezoekt, schrijft de server een regel weg in een logbestand: de logfile
In zo’n regel staat onder andere
-
- User agent (zoals Googlebot, ChatGPTbot, Bingbot, Chrome, Safari)
-
- User agent (zoals Googlebot, ChatGPTbot, Bingbot, Chrome, Safari)

Steeds meer LLM’s (zoals ChatGPT en andere AI-assistenten) gebruiken eigen crawlers om content op te halen en te trainen. In je logfiles zie je precies óf en hoe vaak ze langskomen.
Met andere woorden: Logfiles zijn een volledig logboek van al het verkeer op je site. Inclusief crawlers. En juist dat laatste maakt ze zo interessant voor SEO.
Waarom logfiles zo waardevol zijn voor SEO
In Search Console zie je vertoningen, klikken en wat crawlstatistieken. Handig, maar beperkt. Met logfiles ga je een paar lagen dieper.
Met logfiles kun je veel meer dan alleen technische details terugvinden. Ze laten je namelijk precies zien wat Googlebot op je site doet. Je kijkt niet meer naar je XML-sitemap of wat theorie in een tool, maar naar harde serverrequests. Daardoor zie je bijvoorbeeld welke URL’s écht worden gecrawld, waar je crawlbudget lekt, en of je belangrijkste money pages wel voldoende aandacht krijgen. Dat maakt logfiles meteen één van de meest eerlijke databronnen die je als SEO tot je beschikking hebt.
Een van de grootste voordelen: je kunt je crawlbudget veel slimmer inzetten. Zeker bij grote sites is dat essentieel. Met logfiles ontdek je of tag- en filterpagina’s overdreven vaak worden gecrawld, of oude, irrelevante URL’s nog steeds gevonden door crawlers. Op basis van de informatie uit de logfiles kun je heel gericht ingrijpen en je crawlbudget sturen naar de pagina’s die er wél toe doen.
Logfiles zijn ook ideaal om technische issues te spotten die je in geen enkele andere tool terugziet. Denk aan sporadische 5xx-errors die alleen bij bots optreden, redirect loops die je zelf nooit tegenkomt in de browser of canonicals die in theorie goed staan, maar in de praktijk genegeerd worden omdat Google steeds een andere URL blijft ophalen. In de logs zie je wat de server echt teruggeeft inclusief alle foutcodes en onverwachte reacties.
Daarnaast geven logfiles je een veel realistischer beeld van je indexatiepotentieel. Een simpele vuistregel: wat nooit gecrawld wordt, wordt ook niet geïndexeerd. Door in de logs te kijken, zie je welke content überhaupt een kans maakt om in de index te belanden en welke pagina’s totaal buiten beeld blijven. Dat helpt je om prioriteiten te stellen in content en interne links. Uiteindelijk leveren logfiles je de versie van de waarheid zoals de server die ziet en dus zoals Google je site ervaart.
En het gaat allang niet meer alleen om Google. LLM-crawlers bepalen steeds vaker welke content in AI-antwoorden en assistants terechtkomt. Door in je logfiles te kijken welke AI-bots je site bezoeken, hoeveel ze crawlen en welke delen van je site ze wel of niet zien, krijg je grip op je “zichtbaarheid” buiten de klassieke zoekresultaten om.
Hoe verzamel je logfiles?
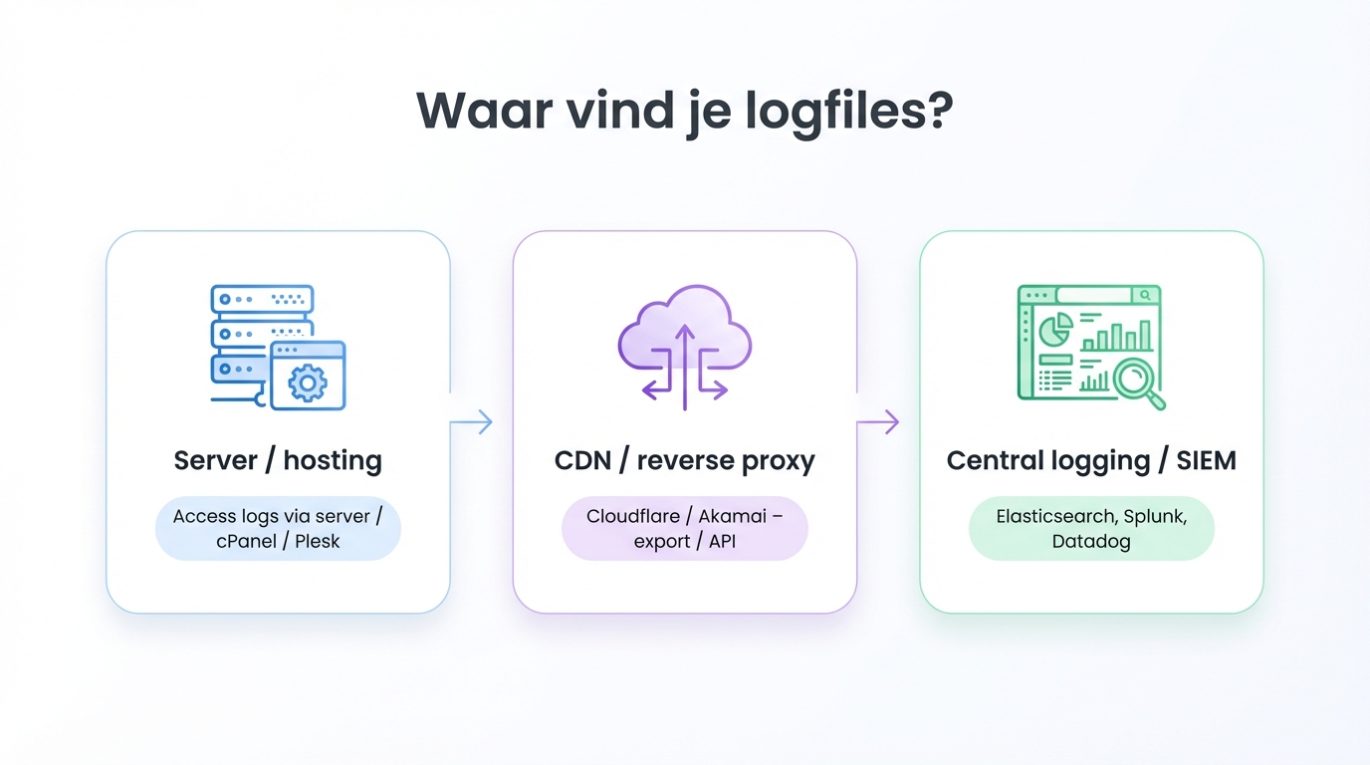
Klinkt leuk, die inzichten, maar dan moet je natuurlijk eerst bij de logfiles kunnen. Hoe je dat doet, hangt af van je hosting en setup, maar grofweg zijn er drie routes.
De meest directe route is via de server zelf. In veel hosting- of serveromgevingen kun je de acces logs gewoon downloaden. Dat gaat bijvoorbeeld via cPanel of Plesk, via de console/SSH, of via een loggingfolder waar periodiek .log- of .gz-bestanden in worden weggezet. Twee dingen zijn daarbij belangrijk: vraag expliciet om access logs (niet alleen error logs) en zorg dat je genoeg historie hebt minimaal 30 dagen, maar liever 60 tot 90.
Werk je met een CDN of reverse proxy, zoals Cloudflare of Akamai, dan lopen veel requests daar doorheen. In dat geval kun je vaak logs exporteren via een dashboard of ontsluiten via een API als je met grote volumes werkt. Let er dan wel op dat je de originele user agent en IP bewaart en dat er geen sampling wordt gebruikt waarbij botverkeer eruit wordt gefilterd. Juist dat botverkeer heb je nodig voor je SEO-analyses.
Bij grotere organisaties worden logs vaak centraal verzameld in logging- of SIEM-tools, zoals Elasticsearch/Kibana, Splunk of Datadog. Dan is het een kwestie van de juiste dataset vinden: zoek naar HTTP access logs, filter op user agents als “Googlebot” en “Bingbot” en exporteer van daaruit een dataset die je kunt gebruiken voor je SEO-analyses. Vaak moet je hier even schakelen met IT of DevOps, maar als je eenmaal een goede exportstroom hebt, wil je niet meer terug.
Waar moet je op letten bij het ophalen van logfiles?
Tijdens de presentatie van Julien kwamen een paar randvoorwaarden langs die je echt niet moet overslaan. Allereerst: privacy en GDPR. Logfiles bevatten IP-adressen en vallen dus onder privacywetgeving. Check met development, IT of legal of IP’s geanonimiseerd moeten worden, hoe en waar logs worden opgeslagen (liefst versleuteld) en hoe lang je ze mag bewaren. Dat voorkomt gedoe achteraf.
Een tweede punt is botvalidatie. Niet alles wat zich als “Googlebot” voordoet, ís ook echt Google. Wil je zuivere data, valideer dan belangrijke bots op IP-range of volg de officiële Google-richtlijnen om bots te verifiëren. Zeker bij grotere sites of wanneer je veel botverkeer ziet, scheelt dat een hoop ruis in je analyses. Hetzelfde geldt voor AI- en LLM-bots: check of de user agents echt horen bij het platform dat je denkt (bijvoorbeeld OpenAI, Microsoft, of andere AI-aanbieders) en documenteer welke je toelaat of blokkeert.
Tot slot: sample niet te agressief. Een paar dagen logfiles is lekker klein en snel te verwerken, maar vaak niet representatief. Zeker niet als je te maken hebt met seizoenseffecten of grote sites waarbij Google het crawlbudget roteert over verschillende delen van de site. Met 30 dagen data kun je al veel beter zien wat structureel is en wat toeval.
Hoe analyseer je logfiles zonder gillend gek te worden?
Ruwe logfiles zijn niet gemaakt om doorheen te lezen als een blog. Je hebt dus minimaal een basisworkflow nodig om ze werkbaar te maken.
De eerste stap is structureren en filteren. Je wilt de logs parseren naar duidelijke kolommen, waarin in elk geval zaken als timestamp, URL, statuscode, user agent, IP en response size netjes uit elkaar worden getrokken. Daarna ga je filteren op bots. Begin met Googlebot, eventueel aangevuld met Googlebot-image of -video als dat relevant is, en andere belangrijke crawlers zoals Bingbot. Voeg daar, waar mogelijk, ook LLM-crawlers aan toe (bijvoorbeeld bots die namens ChatGPT of andere AI-platformen content ophalen). Zo houd je een dataset over die puur gaat over crawlergedrag in plaats van gebruikersverkeer.
De tweede stap is het verrijken van die data met je bestaande SEO-informatie. Dan begint de magie pas echt. Combineer je logs met een URL-crawl (bijvoorbeeld uit Screaming Frog of Sitebulb), met Search Console-data en met je eigen categorisatie van paginatypen (product, categorie, blog, filters, etc.). Voeg bijvoorbeeld een kolom “pagetype” toe, koppel Search Console-URL’s aan de URL’s in je logs en geef aan of een pagina indexeerbaar is, noindex heeft of via canonical wordt toegewezen. Zo kun je veel gerichter interpreteren wat Google waar doet.
Als de data eenmaal strak staat, komt stap drie: visualiseren en segmenteren. Dan kun je gerichte vragen stellen, zoals: hoe verdeelt Googlebot zijn bezoeken per paginatype? Welke statuscodes ziet Google het vaakst? Welke URL’s krijgen nauwelijks of geen crawl-hits? Waar zie je pieken in 5xx- of 404-responses? En welke AI/LLM-crawlers bezoeken mijn site, en welke delen van de site krijgen zij te zien? Die analyses kun je doen in Excel of Google Sheets bij kleinere sites, in BI-tools zoals Looker Studio of Power BI, of in gespecialiseerde SEO log-analysetools bij grotere volumes.
Concrete SEO-use cases met logfiles
Tijdens de sessie in Barcelona kwamen een paar praktijkcases voorbij die je zo op je eigen site kunt toepassen.
Een veelvoorkomend scenario is dat onbelangrijke pagina’s, zoals filter- en zoekresultaatpagina’s of tagpagina’s, bizar veel worden gecrawld, terwijl je belangrijkste categorie- en productpagina’s relatief weinig hits krijgen. Logfiles laten precies zien hoe de crawl-hits verdeeld zijn per type pagina. Zie je overgecrawlde segmenten, dan kun je noindex zetten op onbelangrijke varianten, bepaalde delen (waar veilig) blokkeren in robots.txt of je URL-structuur consolideren. Het effect: Googlebot verschuift z’n aandacht richting de pagina’s die je écht belangrijk vindt.
Een andere sterke use case is het opsporen van orphan pages en vergeten content. Je logfiles kennen vaak pagina’s waarvan jij niet eens meer wist dat ze bestonden. Door alle URL’s in de logs te filteren die wél door Googlebot worden bezocht, maar niet in je crawl of sitemap voorkomen, haal je orphan pages, oude landingspagina’s en per ongeluk live staande test- of staging-URL’s naar boven. Daarna kun je per pagina besluiten: houden, updaten, redirecten of verwijderen. En je voorkomt dat Google eindeloos blijft kauwen op oude pagina’s.
Logfiles helpen ook om technische fouten op te sporen die alleen bots raken. Niet elke error komt in Analytics of in je eigen browser naar boven. In de logs zie je bijvoorbeeld URL’s die bij bots wél een 500 teruggeven (bij serverload, firewallregels of security-oplossingen), redirectloops voor bepaalde user agents of oude URL-patronen waar Google nog steeds op blijft terugkomen. De vervolgstap is dan logisch: structurele 5xx-problemen laten oplossen, nette 301-paden inrichten van oud naar nieuw en zorgen dat belangrijke pagina’s stabiel en foutloos reageren.
Tot slot zijn logfiles ideaal om een prioriteitenlijst te maken voor content- en techniekwerk. Door crawlgedrag te combineren met SEO-metrics, kun je beterkiezen waar je tijd in stopt. Zie je URL’s met veel Googlebot-hits en goede positiepotentie, maar matige content of slechte UX? Dan ligt de focus op content- en UX-verbeteringen. Zie je strategisch belangrijke pagina’s met weinig of geen crawl-hits? Dan zijn interne links, sitemaps en interne campagnes de logische knoppen om aan te draaien.
De belangrijkste learnings op een rij
De kern van Julien z’n verhaal is eigenlijk vrij simpel: logfiles laten zien wat Google daadwerkelijk doet, niet wat jij hoopt dat ‘ie doet. Daardoor krijg je een veel realistischer beeld van crawlgedrag, indexatiepotentieel en technische stabiliteit dan uit alleen tools of sitemaps.
Tools zijn handig, maar je basis is altijd goede data. Of je nu een dedicated log-analysetool gebruikt of gewoon Excel: zorg dat je parsing, filtering en verrijking op orde zijn. Pas dan kun je echt betrouwbare conclusies trekken.
Je hoeft bovendien niet meteen maandelijks een enorm loganalyse-rapport te bouwen. Begin klein, maar begin. Start met 30 dagen logs, focus eerst alleen op Googlebot en stel jezelf een paar concrete vragen: waar zien we veel 404’s, hoe verdeelt de crawl zich over paginatypen, en welke URL’s worden wel gecrawld maar leveren niks op?
Belangrijk om te onthouden: loganalyse is geen eenmalige exercitie. Elke grote release, migratie of structurele wijziging in je site is een aanleiding om opnieuw de logs in te duiken. Crawlt Google de nieuwe structuur zoals bedoeld? Blijven je belangrijkste pagina’s voldoende aandacht krijgen? En ontstaan er nergens onverwachte fouten of loops?
Wat kun je hier nu direct mee?
Begin met het regelen van toegang tot je logfiles. Check bij je hostingpartij, IT of CDN waar de access logs precies staan, in welk formaat ze beschikbaar zijn en over welke periode je ze kunt terughalen. Haal daarna minimaal 30 dagen aan Googlebot-data eruit, filter op user agents met “Googlebot” en zet de belangrijkste velden in een spreadsheet of database.
Beantwoord vervolgens drie simpele vragen: welke paginatypen krijgen de meeste crawl-hits? Waar ziet Google veel 4xx- of 5xx-statuscodes? En welke URL’s worden wel gecrawld, maar leveren nul organisch verkeer op? Vanuit die antwoorden kun je concrete acties formuleren: opschonen, herstructureren, interne links verbeteren of technische bugs laten fixen.
En ja, dit is werk voor iemand die én SEO snapt én niet wegloopt voor data. Maar precies daar ligt ook je toegevoegde waarde als digital marketer.
[ad_2]
Source link